DeepSeek 霸榜 App Store,中國 AI 引發美國科技圈地震的一週

DeepSeek 模型震撼矽谷,含金量還在上升。
作者:APPSO
過去一週,來自中國的 DeepSeek R1 模型攪動整個海外 AI 圈。
一方面,它以較低的訓練成本實現了媲美 OpenAI o1 性能的效果,詮釋了中國在工程能力和規模創新上的優勢;另一方面,它也秉持開源精神,熱衷分享技術細節。
最近,來自加州伯克利大學在讀博士 Jiayi Pan 的研究團隊更是成功地以極低的成本(低於 30 美元)復現了 DeepSeek R1-Zero 的關鍵技術------「頓悟時刻」。

所以也難怪 Meta CEO 扎克伯格、圖靈獎得主 Yann LeCun 以及 Deepmind CEO Demis Hassabis 等人都對 DeepSeek 給予了高度評價。
隨著 DeepSeek R1 的熱度不斷攀升,今天下午,DeepSeek App 因用戶訪問量激增而短暫出現伺服器繁忙的狀況,甚至一度「崩了」。
OpenAI CEO Sam Altman 剛剛也試圖劇透 o3-mini 使用額度,來搶回國際媒體的頭版頭條------ChatGPT Plus 會員每天可查詢 100 次。
然而,鮮為人知的是,在聲名鵲起之前,DeepSeek 母公司幻方量化其實是國內量化私募領域的頭部企業之一。
DeepSeek 模型震撼矽谷,含金量還在上升
2024 年 12 月 26 日,DeepSeek 正式發布了 DeepSeek-V3 大模型。
這款模型在多項基準測試表現優異,超越業內主流頂尖模型,特別是在知識問答、長文本處理、代碼生成和數學能力等方面。例如,在 MMLU、GPQA 等知識類任務中,DeepSeek-V3 的表現接近國際頂尖模型 Claude-3.5-Sonnet。

在數學能力方面,更是在 AIME 2024 和 CNMO 2024 等測試中創造了新的記錄,超越所有已知的開源和閉源模型。同時,其生成速度較上代提升了 200%,達到 60 TPS,大幅改善了用戶體驗。
根據獨立評測網站 Artificial Analysis 的分析,DeepSeek-V3 在多項關鍵指標上超越了其他開源模型,並在性能上與世界頂尖的閉源模型 GPT-4o 和 Claude-3.5-Sonnet 不分伯仲。
DeepSeek-V3 的核心技術優勢包括:
混合專家(MoE)架構:DeepSeek-V3 擁有 6710 億參數,但在實際運行中,每個輸入僅激活 370 億參數,這種選擇性激活的方式大大降低了計算成本,同時保持了高性能。
多頭潛在注意力(MLA):該架構在 DeepSeek-V2 中已經得到驗證,能夠實現高效的訓練和推理。
無輔助損失的負載平衡策略:這一策略旨在最小化因負載平衡對模型性能產生的負面影響。
多tokens預測訓練目標:該策略提升了模型的整體性能。
高效的訓練框架:採用 HAI-LLM 框架,支持 16-way Pipeline Parallelism(PP)、64-way Expert Parallelism(EP)和 ZeRO-1 Data Parallelism(DP),並通過多種優化手段降低了訓練成本。
更重要的是,DeepSeek-V3 的訓練成本僅為 558 萬美元,遠低於如訓練成本高達 7800 萬美元的 GPT-4。並且,其 API 服務價格也延續了過往親民的打法。

輸入 tokens 每百萬僅需 0.5元(快取命中)或 2 元(快取未命中),輸出 tokens 每百萬僅需 8 元。
《金融時報》將其描述為「震驚國際科技界的黑馬」,認為其性能已與資金雄厚的 OpenAI 等美國競爭對手模型相媲美。Maginative 創始人 Chris McKay 更進一步指出,DeepSeek-V3 的成功或將重新定義 AI 模型開發的既定方法。
換句話說,DeepSeek-V3 的成功也被視為對美國算力出口限制的直接回應,這種外部壓力反而刺激了中國的創新。
DeepSeek 創始人梁文鋒,低調的浙大天才
DeepSeek 的崛起讓矽谷寝食難安,這個攪動全球 AI 行業模型的背後創始人梁文鋒則完美詮釋了中國傳統意義上天才的成長軌跡------少年功成,歷久彌新。
一個好的 AI 公司領導者,需要既懂技術又懂商業,既要有遠見又要務實,既要有創新勇氣又要有工程紀律。這種複合型人才本身就是稀缺資源。
17 歲考入浙江大學信息與電子工程學專業,30 歲創辦幻方量化(Hquant),開始帶領團隊探索全自動量化交易。梁文鋒的故事印證了天才總會在正確的時間做對的事。

2010 年:隨著滬深 300 股指期貨推出,量化投資迎來發展機遇,幻方團隊乘勢而上,自營資金迅速增長。
2015 年:梁文鋒與校友共同創立幻方量化,次年推出首個 AI 模型,上線深度學習生成的交易倉位。
2017 年:幻方量化宣稱實現投資策略全面 AI 化。
2018 年:確立 AI 為公司主要發展方向。
2019 年:資金管理規模突破百億元,成為國內量化私募「四巨頭」之一。
2021 年:幻方量化成為國內首家突破千億規模的量化私募大廠。
你不能只在成功的時候才想起這家公司在過去幾年坐冷板凳的日子。不過,就像量化交易公司轉型 AI,看似意外,實則順理成章 ------ 因為它們都是數據驅動的技術密集型行業。
黃仁勳只想賣遊戲顯卡,賺我們這些臭打遊戲的三瓜兩棗,卻沒想到成了全球最大的 AI 軍火庫,幻方踏進 AI 領域也是何其相似。這種演進比當下許多行業生搬硬套 AI 大模型更有生命力。
幻方量化在量化投資過程中積累了大量數據處理和算法優化經驗,同時擁有大量 A100 芯片,為 AI 模型訓練提供了強大硬體支持。從 2017 年開始,幻方量化大規模佈局 AI 算力,搭建「螢火一號」「螢火二號」等高性能計算集群,為 AI 模型訓練提供強大算力支持。

2023 年,幻方量化正式成立 DeepSeek,專注於 AI 大模型研發。DeepSeek 繼承了幻方量化在技術、人才和資源方面的積累,迅速在 AI 領域嶄露頭角。
在接受《暗涌》的深度訪談中,DeepSeek 創始人梁文鋒同樣展現出獨特的戰略視野。
不同於大多數選擇複製 Llama 架構的中國公司,DeepSeek 直接從模型結構入手,只為瞄準 AGI 的宏偉目標。
梁文鋒毫不掩飾當前的差距,當前中國 AI 與國際頂尖水平存在顯著差距,在模型結構、訓練動力學和數據效率上的綜合差距導致需要投入 4 倍的算力才能達到同等效果。

▲圖片來自央視新聞截圖
這種直面挑戰的態度源於梁文鋒在幻方多年的經驗積累。
他強調,開源不僅是技術分享,更是一種文化表達,真正的護城河在於團隊的持續創新能力。DeepSeek 獨特的組織文化鼓勵自下而上的創新,淡化層級,重視人才的熱情和創造力。
團隊主要由頂尖高校的年輕人組成,採用自然分工模式,讓員工自主探索和協作。在招聘時更看重員工的熱愛和好奇心,而非傳統意義上的經驗和背景。
對於行業前景,梁文鋒認為 AI 正處於技術創新的爆發期,而非應用爆發期。他強調,中國需要更多原創技術創新,不能永遠處於模仿階段,需要有人站到技術前沿。
即使 OpenAI 等公司目前處於領先地位,但創新的機會仍然存在。

捲翻矽谷,DeepSeek 讓海外 AI 圈坐立不安
儘管業界對 DeepSeek 的評價不盡相同,但我們也搜集了一些業內人士的評價。
英偉達 GEAR Lab 項目負責人 Jim Fan 對 DeepSeek-R1 給予了高度評價。
他指出這代表著非美國公司正在踐行 OpenAI 最初的開放使命,通過公開原始算法和學習曲線等方式實現影響力,順便還內涵了一波 OpenAI。
DeepSeek-R1 不僅開源了一系列模型,還披露了所有訓練秘密。它們可能是首個展示 RL 飛輪重大且持續增長的開源項目。
影響力既可以通過『ASI 內部實現』或『草莓計畫』等傳說般的項目實現,也可以簡單地通過公開原始算法和 matplotlib 學習曲線來達成。
華爾街頂級風投 A16Z 創始人 Marc Andreesen 則認為 DeepSeek R1 是他所見過的最令人驚奇和令人印象深刻的突破之一,作為開源,這是給世界的一份意義深遠的禮物。

騰訊前高級研究員、北京大學人工智能方向博士後盧菁從技術積累的角度進行分析。他指出 DeepSeek 並非突然爆火,它承接了上一代模型版本中的很多創新,相關模型架構、算法創新經過迭代驗證,震動行業也有其必然性。
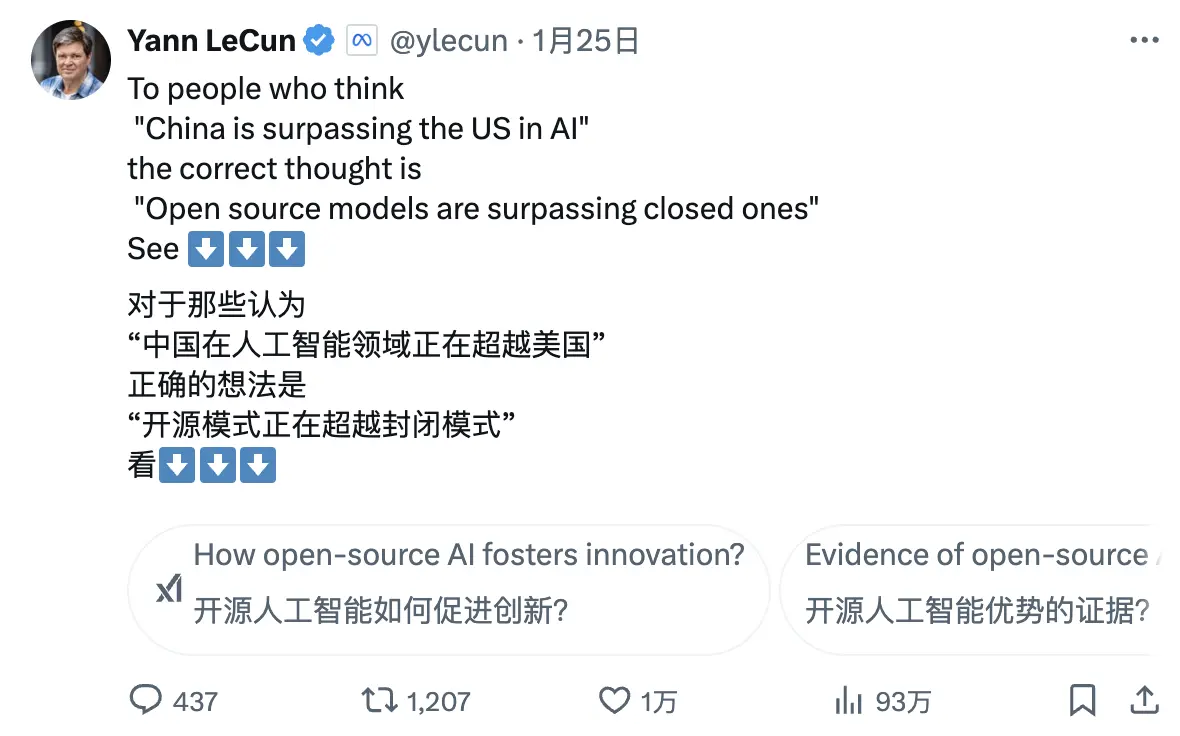
圖靈獎得主、Meta 首席 AI 科學家 Yann LeCun 則提出了一個新的視角:
「給那些看到 DeepSeek 的表現後,覺得「中國在 AI 方面正在超越美國」的人,你們的解讀是錯的。正確的解讀應該是,「開源模型正在超越專有模型」。」
Deepmind CEO Demis Hassabis 的評價則透露出一絲憂慮:
「它(DeepSeek)取得的成就令人印象深刻,我認為我們需要考慮如何保持西方前沿模型的領先地位,我認為西方仍然領先,但可以肯定的是,中國具有極強的工程和規模化能力。」
微軟 CEO Satya Nadella 在瑞士達沃斯世界經濟論壇上表示,DeepSeek 切實有效地開發出了一款開源模型,不僅在推理計算方面表現出色,而且超級計算效率極高。
他強調,微軟必須以最高度的重視來應對中國的這些突破性進展。
Meta CEO 扎克伯格評價則更加深入,他認為 DeepSeek 展現出的技術實力和性能令人印象深刻,並指出中美之間的 AI 差距已經微乎其微,中國的全力衝刺使得這場競爭愈發激烈。
來自競爭對手的反應或許是對 DeepSeek 最好的認可。據 Meta 員工在匿名職場社區 TeamBlind 上的爆料,DeepSeek-V3 和 R1 的出現讓 Meta 的生成式 AI 團隊陷入了恐慌。
Meta 的工程師們正在爭分奪秒地分析 DeepSeek 的技術,試圖從中複製任何可能的技術。
原因在於 DeepSeek-V3 的訓練成本僅為 558 萬美元,這個數字甚至不及 Meta 某些高管的年薪。如此懸殊的投入產出比,讓 Meta 管理層在解釋其龐大的 AI 研發預算時倍感壓力。

國際主流媒體對 DeepSeek 的崛起也給予了高度關注。
《金融時報》指出,DeepSeek 的成功顛覆了「AI 研發必須依賴巨額投入」的傳統認知,證明精準的技術路線同樣能實現卓越的研究成果。更重要的是,DeepSeek 團隊對技術創新的無私分享,讓這家更注重研究價值的公司成為了一個格外強勁的競爭對手。
《經濟學人》表示,認為中國 AI 技術在成本效益方面的快速突破,已經開始動搖美國的技術優勢,這可能會影響美國未來十年的生產力提升和經濟增長潛力。

《紐約時報》則從另一個角度切入,DeepSeek-V3 在性能上與美國公司的高端聊天機器人相當,但成本大大降低。
這表明即使在芯片出口管制的情況下,中國公司也能通過創新和高效利用資源來競爭。並且,美國政府的芯片限制政策可能適得其反,反而推動了中國在開源 AI 技術領域的創新突破。
DeepSeek「報錯家門」,自稱是 GPT-4
在一片讚譽聲中,DeepSeek 也面臨著一些爭議。
不少外界人士認為 DeepSeek 可能在訓練過程中使用了 ChatGPT 等模型的輸出數據作為訓練材料,通過模型蒸餾技術,這些數據中的「知識」被遷移到 DeepSeek 自己的模型中。
這種做法在 AI 領域並非罕見,但質疑者關注的是 DeepSeek 是否在未充分披露的情況下使用了 OpenAI 模型的輸出數據。這似乎在 DeepSeek-V3 的自我認知上也有所體現。
早前就有用戶發現,當詢問模型的身份時,它會將自己誤認為是 GPT-4。

高質量數據一直是 AI 發展的重要因素,就連 OpenAI 也難以避免數據獲取的爭議,其從互聯網大規模爬取數據的做法同樣因此吃了許多版權官司,截至目前,OpenAI 與紐約時報的一審裁決尚未靴子落地,又再添新案。
所以 DeepSeek 也因此遭到了 Sam Altman 和 John Schulman 的公開內涵。
「複製你知道行得通的東西是(相對)容易的。當你不知道它是否行得通時,做一些新的、有風險的、困難的事情是非常困難的。」

不過,DeepSeek 團隊在 R1 的技術報告中明確表示未使用 OpenAI 模型的輸出數據,並表示通過強化學習和獨特的訓練策略實現了高性能。
例如,採用了多階段訓練方式,包括基礎模型訓練、強化學習(RL)訓練、微調等,這種多階段循環訓練方式有助於模型在不同階段吸收不同的知識和能力。
省錢也是技術活,DeepSeek 背後技術的可取之道
DeepSeek-R1 技術報告裡提到一個值得關注的發現,那就是 R1 zero 訓練過程裡出現的「aha moment(頓悟時刻)」。在模型的中期訓練階段,DeepSeek-R1-Zero 開始主動重新評估初始解題思路,並分配更多時間優化策略(如多次嘗試不同解法)。
換句話說,通過 RL 框架,AI 可能自發形成類人推理能力,甚至超越預設規則的限制。並且這也將有望為開發更自主、自適應的 AI 模型提供方向,比如在複雜決策(醫療診斷、算法設計)中動態調整策略。

與此同時,許多業內人士正試圖深入解析 DeepSeek 的技術報告。OpenAI 前聯創 Andrej Karpathy 則在 DeepSeek V3 發布後曾表示:
DeepSeek(這家中國的 AI 公司)今天讓人感到輕鬆,它公開發布了一個前沿級的語言模型(LLM),並且在極低的預算下完成了訓練(2048個GPU,持續 2 個月,花費 600 萬美元)。
作為參考,這種能力通常需要 16K 個 GPU 的集群來支持,而現在這些先進的系統大多都使用大約 100K 個 GPU。例如,Llama 3(405B參數)使用了 3080 萬個 GPU 小時,而 DeepSeek-V3 似乎是一個更強大的模型,僅用了 280 萬個 GPU 小時(約為 Llama 3 的 1/11 計算量)。
如果這個模型在實際測試中也表現出色(例如,LLM 競技場排名正在進行,我的快速測試表現不錯),那麼這將是一個在資源受限的情況下,展現出研究和工程能力的非常令人印象深刻的成果。
那麼,這是不是意味著我們不再需要大型 GPU 集群來訓練前沿 LLM 了?並非如此,但它表明,你必須確保自己使用的資源不浪費,這個案例展示了數據和算法優化仍然能帶來很大進展。此外,這份技術報告也非常精彩和詳細,值得一讀。

面對 DeepSeek V3 被質疑使用 ChatGPT 數據的爭議,Karpathy 則表示,大語言模型本質上並不具備人類式的自我意識,模型是否能正確回答自己身份,完全取決於開發團隊是否專門構建了自我認知訓練集,如果沒有特意訓練,模型會基於訓練數據中最接近的信息作答。
此外,模型將自己識別為 ChatGPT 並非問題所在,考慮到 ChatGPT 相關數據在互聯網上的普遍性,這種回答實際上反映了一種自然的「鄰近知識湧現」現象。
Jim Fan 在閱讀 DeepSeek-R1 的技術報告過後則指出:
這篇論文的最重要觀點是:完全由強化學習驅動,完全沒有任何監督學習(SFT)的參與,這種方法類似於 AlphaZero------通過「冷啟動(Cold Start)」從零開始掌握圍棋、將棋和國際象棋,而不需要模仿人類棋手的下法。
-- 使用基於硬編碼規則計算的真實獎勵,而不是那些容易被強化學習"破解"的學習型獎勵模型。
-- 模型的思考時間隨著訓練進程的推進穩步增加,這不是預先編程的,而是一種自發的特性。
-- 出現了自我反思和探索行為的現象。
-- 使用 GRPO 代替 PPO:GRPO 去除了 PPO 中的評論員網絡,轉而使用多個樣本的平均獎勵。這是一種簡單的方法,可以減少記憶體使用。值得注意的是,GRPO 是由 DeepSeek 團隊在 2024 年 2 月發明的,真的是一個非常強大的團隊。
同一天 Kimi 也發布了類似的研究成果時,Jim Fan 發現兩家公司的研究殊途同歸:
都放棄了 MCTS 等複雜樹搜索方法,轉向更簡單的線性化思維軌跡,採用傳統的自回歸預測方式
都避免使用需要額外模型副本的價值函數,降低了計算資源需求,提高了訓練效率
都摒棄密集的獎勵建模,儘可能依靠真實結果作為指導,確保了訓練的穩定性

但兩者也存在顯著差異:
DeepSeek 採用 AlphaZero 式的純 RL 冷啟動方法,Kimi k1.5 選擇 AlphaGo-Master 式的預熱策略,使用輕量級 SFT
DeepSeek 以 MIT 協議開源,Kimi 則在多模態基準測試中表現出色,論文系統設計細節上更為豐富,涵蓋 RL 基礎設施、混合集群、代碼沙箱、並行策略
不過,在這個快速迭代的 AI 市場中,領先優勢往往稍縱即逝。其他模型公司必將迅速汲取 DeepSeek 的經驗並加以改進,或許很快就能迎頭趕上。
大模型價格戰的發起者
很多人都知道 DeepSeek 有一個名為「AI 屆拼多多」的稱號,卻並不知道這背後的含義其實源於去年打響的大模型價格戰。
2024 年 5 月 6 日,DeepSeek 發布了 DeepSeek-V2 開源 MoE 模型,通過如 MLA(多頭潛在注意力機制)和 MoE(混合專家模型)等創新架構,實現了性能與成本的雙重突破。
推理成本被降至每百萬 token 僅 1 元人民幣,約為當時 Llama3 70B 的七分之一,GPT-4 Turbo 的七十分之一。這種技術突破使得 DeepSeek 能夠在不貼錢的情況下,提供極具性價比的服務,同時也給其他廠商帶來了巨大的競爭壓力。
DeepSeek-V2 的發布引發了連鎖反應,字節跳動、百度、阿里、騰訊、智譜 AI 紛紛跟進,大幅下調其大模型產品的價格。這場價格戰的影響力甚至跨越太平洋,引起了矽谷的高度關注。
DeepSeek 也因此被冠以「AI 屆的拼多多」之稱。

面對外界的質疑,DeepSeek 創始人梁文鋒在接受暗涌的採訪時回應稱:
「搶用戶並不是我們的主要目的。我們降價一方面是因為我們在探索下一代模型的結構中,成本先降下來了;另一方面,我們也覺得無論是 API 還是 AI,都應該是普惠的、人人可以用得起的東西。」
事實上,這場價格戰的意義遠超競爭本身,更低的準入門檻讓更多企業和開發者得以接觸和應用前沿 AI,同時也倒逼整個行業重新思考定價策略,正是在這個時期,DeepSeek 開始進入公眾視野,嶄露頭角。
千金买马骨,雷軍挖角 AI 天才少女
幾週前,DeepSeek 還出現了一個引人注目的人事變動。
據第一財經報導,雷軍花千萬年薪以千萬年薪成功挖角了羅福莉,並委以小米 AI 實驗室大模型團隊負責人重任。
羅福莉於 2022 年加入幻方量化旗下的 DeepSeek,在 DeepSeek-V2 和最新的 R1 等重要報告中都能看到她的身影。

再後來,一度專注於 B 端的 DeepSeek 也開始佈局 C 端,推出移動應用。截至發稿前,DeepSeek 的移動應用在蘋果 App Store 免費版應用最高排到第二,展現出強勁的競爭力。
一連串的小高潮讓 DeepSeek 聲名鵲起,但同時也在疊加著更高的高潮,1 月 20 日晚,擁有 660B 參數的超大規模模型 DeepSeek R1 正式發布。
這款模型在數學任務上表現出色,如在 AIME 2024 上獲得 79.8% 的 pass@1 得分,略超 OpenAI-o1;在 MATH-500 上得分高達 97.3%,與 OpenAI-o1 相當。
編程任務方面,如 Codeforces 上獲得 2029 Elo 評級,超越 96.3%的人類參與者。在 MMLU、MMLU-Pro 和 GPQA Diamond 等知識基準測試中,DeepSeek R1 得分分別為 90.8%、84.0% 和 71.5%,雖略低於 OpenAI-o1,但優於其他閉源模型。
在最新公布的大模型競技場 LM Arena 的綜合榜單中,DeepSeek R1 排名第三,與 o1 並列。
在「Hard Prompts」(高難度提示詞)、「Coding」(代碼能力)和「Math」(數學能力)等領域,DeepSeek R1 位列第一。
在「Style Control」(風格控制)方面,DeepSeek R1 與 o1 並列第一。
在「Hard Prompt with Style Control」(高難度提示詞與風格控制結合)的測試中,DeepSeek R1 也與 o1 並列第一。

在開源策略上,R1 採用 MIT License,給予用戶最大程度的使用自由,支持模型蒸餾,可將推理能力蒸餾到更小的模型,如 32B 和 70B 模型在多項能力上實現了對標 o1-mini 的效果,開源力度甚至超越了此前一直被詬病的 Meta。
DeepSeek R1 的橫空出世,讓國內用戶首次能夠免費使用到媲美 o1 級別的模型,打破了長期存在的信息壁壘。其在小紅書等社交平台掀起的討論熱潮,堪比發布之初的 GPT-4 。
走出海去,去內卷
回望 DeepSeek 的發展軌跡,其成功密碼清晰可見,實力是基礎,但品牌認知才是護城河。
在與《晚點》的對話中,MiniMax CEO 閻俊杰深入分享了他對 AI 行業的思考和公司戰略的轉變。他強調了兩個關鍵轉折點:一是認識到技術品牌的重要性,二是理解開源策略的價值。
閻俊杰認為在 AI 領域,技術進化速度比當前成就更重要,而開源可以通過社區反饋加速這一進程;其次,強大的技術品牌對吸引人才、獲取資源至關重要。
以 OpenAI 為例,儘管後期遭遇管理層動盪,但其早期樹立的創新形象和開源精神已為其積攢了第一波好印象。即便 Claude 後續在技術上已勢均力敵,逐步蠶食 OpenAI 的 B 端用戶,但憑藉著用戶的路徑依賴,OpenAI 依然在 C 端用戶上遙遙領先。
在 AI 領域,真正的競爭舞台永遠在全球,走出海去,去內卷,去宣傳也是一條不折不扣的好路。

這股出海浪潮早已在業內激起漣漪,更早時候的 Qwen、面壁智能、以及最近 DeepSeek R1、kimi v1.5、豆包 v1.5 Pro 都早已在海外鬧起了不小的動静。
2025 年雖被冠上了智能體元年,AI 眼鏡元年等諸多標籤,但今年也將是中國 AI 企業擁抱全球市場的重要元年,走出去將成為繞不開的關鍵詞。
並且,開源策略也是一步好棋,吸引了大量技術博主和開發者自發成為 DeepSeek 的「自來水」,科技向善,不該只是口號,從「AI for All」的口號到真正的技術普惠,DeepSeek 走出了一條比 OpenAI 更純粹的道路。
如果說 OpenAI 讓我們看到了 AI 的力量,那麼 DeepSeek 則讓我們相信:
這股力量終將惠及每個人。
免責聲明:文章中的所有內容僅代表作者的觀點,與本平台無關。用戶不應以本文作為投資決策的參考。
您也可能喜歡
以太坊期權交易者準備迎接三月下滑,對沖更深層次的損失
快速摘要 以太坊期權市場波動性的變化以及下行保護溢價的上升顯示出對三月份的看跌前景,促使交易者以更謹慎的策略對進一步的價格下跌進行對沖。本週,以太坊價格波動讓加密原生期權交易者措手不及,導致期權的顯著重新定價,這表明市場預期近期價格波動將加劇。

比特幣礦商TeraWulf的股價在年收入增長102%後上漲
截至12月31日,該比特幣礦工在資產負債表上擁有2.745億美元的現金及現金等價物和比特幣。

報告:貝萊德將比特幣ETF納入面向財務顧問的投資組合
快速摘要 貝萊德正在將其現貨比特幣交易所交易基金IBIT添加到資產管理公司向財務顧問推廣的某些“模型”投資組合中。此舉可能會為IBIT帶來額外需求,該基金是按管理資產計算的最大現貨比特幣ETF。隨著加密貨幣價格在最近幾天的市場調整中回落,IBIT在週三創下了4.181億美元的淨流出紀錄。

BTCC 參展 Token2049 杜拜站,超豪華獎勵等你贏
